Claude Opus 4.6 -- model AI, ktory sprawil, ze programisci zaczeli sie bac o swoja prace
Claude Opus 4.6 -- model AI, ktory sprawil, ze programisci zaczeli sie bac o swoja prace
Claude Opus 4.6 -- model AI, ktory sprawil, ze programisci zaczeli sie bac o swoja prace
Wyobraz sobie, ze dajesz AI dostep do calego kodu swojej firmy -- miliony linii, tysiace plikow -- i mowisz: "napraw to". Nie fragment. Nie jeden plik. Calosc. A model odpowiada: "Juz robie. Wyslalem czterech agentow, kazdy pracuje na osobnej galezi. Daj mi godzine."
To nie science fiction. To Claude Opus 4.6, najnowszy model Anthropic, ktory od 5 lutego 2026 roku zmienia zasady gry w branzy AI. Wyniki benchmarkow sa tak dobre, ze inwestorzy software'owi zaczeli panikowac -- fundusz WisdomTree Cloud Computing stracil ponad 20% wartosci od poczatku roku. CNBC nazywa to poczatkiem ery "vibe working" -- pracy, w ktorej AI nie asystuje, lecz wykonuje zadania.
Sprawdzmy twarde dane.
Milion tokenow kontekstu -- i nie, to nie marketing
Kazdy producent modeli AI lubi rzucac duzymi liczbami. Roznica polega na tym, czy model faktycznie uzywa calego kontekstu, czy tylko udaje, ze go rozumie.
Claude Opus 4.6 jako pierwszy model klasy Opus oferuje okno kontekstowe 1 000 000 tokenow (w wersji beta). To odpowiednik okolo 750 powiesci, calego kodu zrodlowego duzej aplikacji enterprise albo pelnego zestawu dokumentow prawnych -- przetworzonych w jednym zapytaniu.
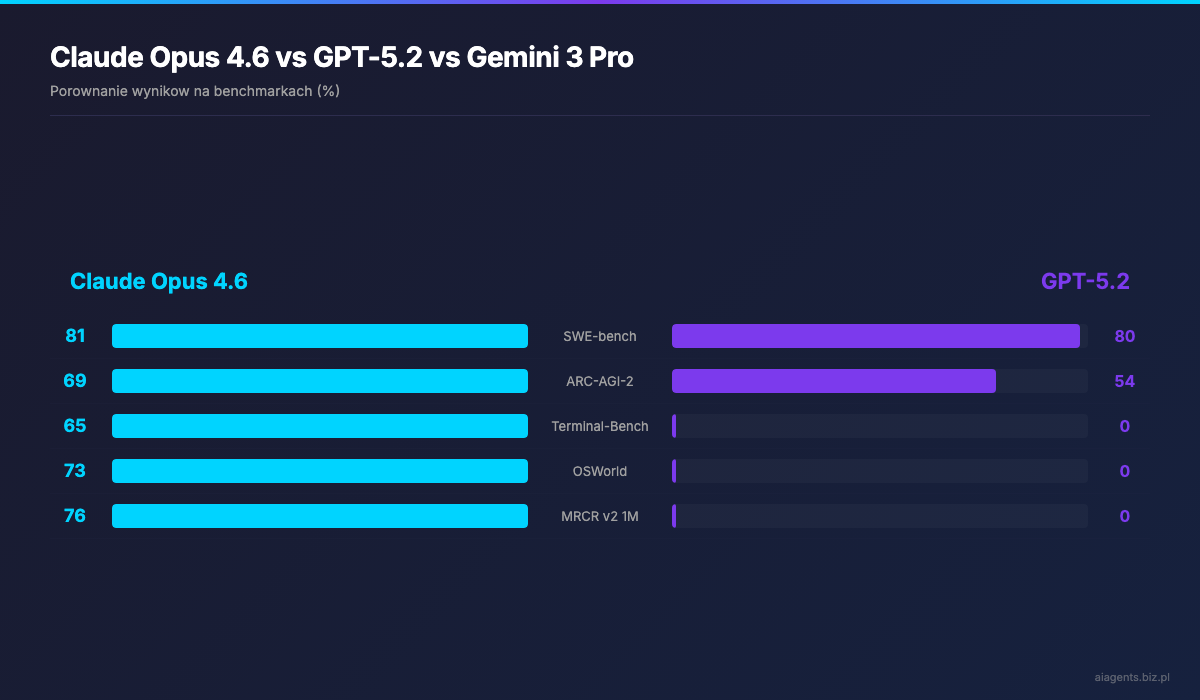
Ale prawdziwy test to nie pojemnosc, lecz jakosc. Na benchmarku MRCR v2 (test odnajdywania konkretnych informacji ukrytych w ogromnym tekście), Opus 4.6 osiagnal 76% skutecznosci na wariancie z 8 "iglami" w milionie tokenow. Poprzedni Sonnet 4.5? Zaledwie 18.5%. To nie jest przyrostowa poprawa -- to zupelnie inna klasa zdolnosci.
Dla porownania -- okna kontekstowe konkurencji:
- Claude Opus 4.6: 1M tokenow (beta), standardowo 200K
- Gemini 3 Pro: 1M tokenow
- GPT-5.2: 128K tokenow -- prawie 8x mniej
Co wazne, dlugi kontekst nie jest darmowy. Prompty powyzej 200K tokenow to tier premium ($10/$37.50 za milion tokenow input/output). Anthropic nie sponsoruje power userow -- ale za to daje im narzedzie, ktore naprawde dziala.
Benchmarki, ktore napedzily inwestorom strachu
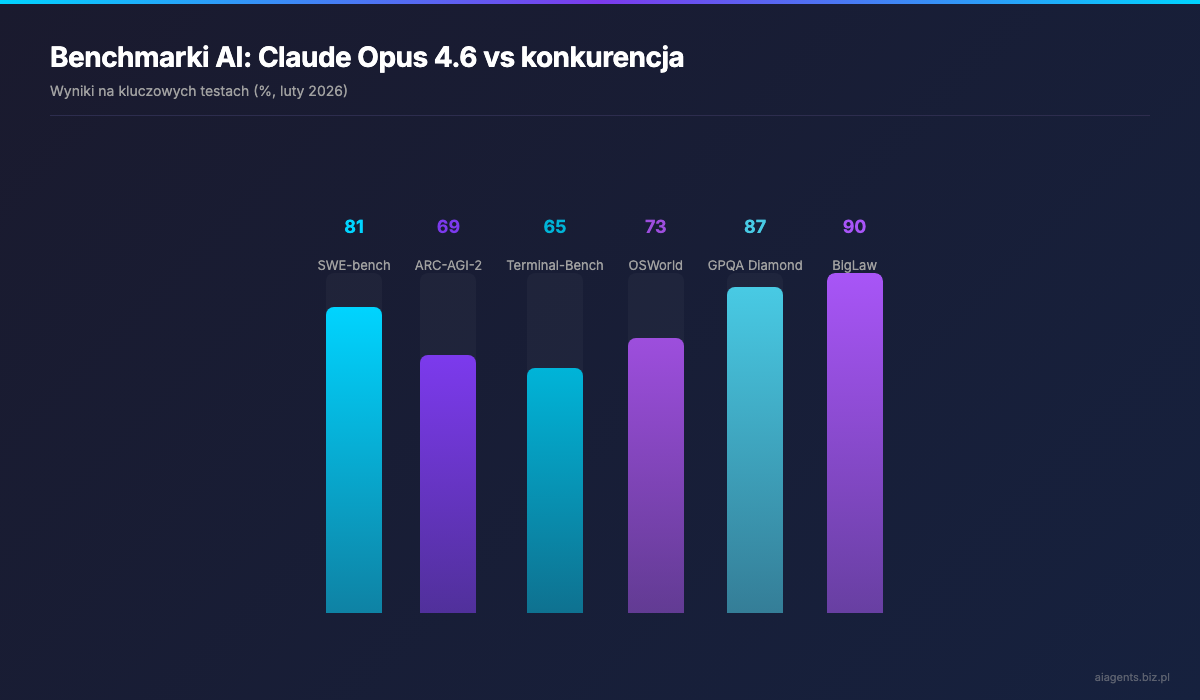
Opus 4.6 nie wygrywa jednego czy dwoch testow. Dominuje w prawie kazdej kategorii, szczegolnie tam, gdzie liczy sie autonomiczna praca i rozumowanie.
Agentic coding -- tu Claude jest krolem
- Terminal-Bench 2.0: 65.4% -- najwyzszy wynik w branzy (poprzednio 59.8% dla Opus 4.5)
- SWE-bench Verified: 80.8% -- rozwiazywanie realnych issues z GitHuba
- OSWorld (autonomiczne uzycie komputera): 72.7% (skok z 66.3%)
- MCP Atlas (skalowalne uzycie narzedzi): 62.7%
Rozumowanie abstrakcyjne -- ARC-AGI-2
Ten benchmark jest szczegolny, bo testuje zdolnosc do generalizacji -- rozwiazywania problemow, ktorych model nigdy wczesniej nie widzial. Opus 4.6 zdobyl 68.8%. Dla porownania:
- Claude Opus 4.5: 37.6% (prawie dwukrotnie gorzej)
- GPT-5.2: 54.2%
- Gemini 3 Pro: 45.1%
Ten skok z 37.6% do 68.8% miedzy generacjami to cos bezprecedensowego w historii AI.
Praca profesjonalna -- GDPval-AA
Na benchmarku GDPval-AA, ktory mierzy wydajnosc w realnych zadaniach z 44 zawodow (finanse, prawo, analityka), Opus 4.6 jest o 144 punkty Elo lepszy niz GPT-5.2 i o 190 punktow lepszy niz wlasny poprzednik. To jak porownanie szachisty z rankingiem 2800 do gracza z 2600 -- roznica, ktora czujesz w kazdej partii.
Dodatkowe rekordy
- BrowseComp (wyszukiwanie trudno dostepnych informacji online): najlepszy wynik
- Humanity's Last Exam (multidyscyplinarne rozumowanie): lider
- BigLaw Bench (rozumowanie prawnicze): 90.2% -- najwyzszy wynik wsrod wszystkich modeli Claude
- Finance Agent: najlepszy wynik w branzy w zadaniach analityka finansowego
- CyberGym: najlepsze wykrywanie realnych luk w kodzie
Agent Teams -- koniec ery "jednego asystenta"

To jest funkcja, ktora naprawde zmienia paradygmat. Agent Teams (dostepne w research preview) pozwalaja uruchomic zespol rownoleglych agentow AI w Claude Code, z ktorych kazdy pracuje na osobnej galezi git (worktree).
Scott White, Head of Product w Anthropic, porownuje to do posiadania utalentowanego zespolu ludzi: "Zamiast jednego agenta pracujacego sekwencyjnie, mozesz podzielic prace miedzy wielu agentow -- kazdy jest wlascicielem swojego kawalka i koordynuja sie bezposrednio."
Praktyczny przyklad: refaktoring duzej aplikacji
Wyobrazmy sobie migracje legacy systemu:
- Agent 1 analizuje backend i proponuje zmiany w API
- Agent 2 aktualizuje i pisze nowe testy jednostkowe
- Agent 3 przeszukuje dokumentacje, generuje changelog i migracje bazy danych
- Agent 4 skanuje kod pod katem luk bezpieczenstwa
Wszystko dzieje sie rownolegle. Programista moze przejmowac kontrole nad dowolnym agentem w czasie rzeczywistym (Shift+Up/Down lub tmux). Jedna z firm testujacych raportowala, ze Opus 4.6 "obsluzywal migracje bazy kodu liczacej miliony linii jak senior inzynier -- zaplanowal z gory, adaptowal strategie na biezaco i skonczyl w polowie czasu."
Inny testujacy: "Opus 4.6 autonomicznie zamknal 13 issues i przypisal 12 do wlasciwych czlonkow zespolu w jeden dzien, zarzadzajac organizacja ~50 osob w 6 repozytoriach."
Nieskonczone konwersacje dzieki Context Compaction
Dlugo dzialajace agenty AI zawsze mialy jeden problem: w koncu trafialy w limit kontekstu i "zapominaly" poczatek rozmowy. Nowa funkcja Context Compaction (w beta) automatycznie podsumowuje starszy kontekst, gdy rozmowa zbliza sie do limitu.
W praktyce oznacza to, ze agent moze pracowac teoretycznie w nieskonczonosc -- bez utraty kluczowych informacji. Polacz to z milionowym oknem kontekstu i Agent Teams, a otrzymujesz system, ktory moze samodzielnie prowadzic wielodniowe projekty.
Dodatkowa nowoscia jest Adaptive Thinking -- model sam decyduje, kiedy myslec gleblej. Cztery poziomy wysilku (low, medium, high, max) daja developerom pelna kontrole nad balansem miedzy inteligencja, szybkoscia i kosztem.
500 luk zero-day znalezionych przed premiera
Bezpieczenstwo to DNA Anthropic -- i Opus 4.6 to potwierdza w sposob, ktory budzi jednoczesnie podziw i niepokoj.
Przed premiera model przeszedl najobszerniejszy zestaw testow bezpieczenstwa w historii firmy. W ramach tych testow Opus 4.6 samodzielnie odkryl ponad 500 wczesniej nieznanych luk zero-day w popularnym oprogramowaniu open-source -- od bledow powodujacych awarie systemu po uszkodzenia pamieci w narzedziach takich jak GhostScript i OpenSC.
Jak ujal to Logan Graham, szef zespolu red team w Anthropic: "To wyscig miedzy obroncami a atakujacymi, i chcemy, zeby obroncy mieli narzedzia pierwsi."
Wynik? Claude Code Security -- nowa funkcja pozwalajaca zespolom skanowac bazy kodu i proponowac poprawki, ktore tradycyjne narzedzia czesto pomijaja. Na benchmarku CyberGym Claude znajduje realne luki lepiej niz jakikolwiek inny model.
Co wazne, przy tych zaawansowanych zdolnosciach, wskaznik niebezpiecznych zachowan modelu pozostaje na najnizszym poziomie w branzy, a wskaznik nadmiernej odmowy (over-refusal) jest rowniez najnizszy wsrod ostatnich modeli Claude.
Enterprise: 70% Fortune 100 juz korzysta z Claude
Adopcja Claude w sektorze korporacyjnym rosnie w tempie, ktore powinno niepokoic konkurencje:
- 30 milionow aktywnych uzytkownikow miesiecznie
- 70% firm z listy Fortune 100 korzysta z Claude
- 80% przychodu Anthropic pochodzi od klientow enterprise (wedlug CEO Dario Amodei)
- 29% udzialu w rynku asystentow AI dla firm
- 6000+ aplikacji zintegrowanych z Claude, 75+ gotowych konektorow
- Cognizant: 350 000 pracownikow wyposazonych w Claude
- Accenture: 30 000 pracownikow przeszkolonych
- 41-68% developerow korzysta z Claude lub Claude Code w codziennej pracy (Faros AI, 2026)
- 92% wskaznik satysfakcji wsrod uzytkownikow
Warto tez wspomniec o nowych integracjach produktowych. Claude w Excelu obsluguje teraz dlugotrwale zadania i nieustrukturyzowane dane. Claude w PowerPoincie (research preview) czyta layouty i master slajdow, utrzymujac spojnosc wizualna marki. To nie sa demka badawcze -- to narzedzia gotowe do codziennej pracy w korporacji.
Rownolegle rozwija sie Cowork -- tryb, w ktorym Claude dziala autonomicznie, wykonujac wiele zadan jednoczesnie: analizy finansowe, research, tworzenie dokumentow i prezentacji. Jak powiedzial Scott White: "Claude przeszedl od modelu, z ktorym mozna porozmawiac, do czegos, czemu mozna powierzyc prawdziwa, znaczaca prace."
Anthropic nie jest juz startupem z ambicjami. To firma, ktora definiuje standardy pracy z AI w sektorze enterprise -- i ma na to twarde dane.
Cennik: wiecej mocy za te sama cene
Anthropic zdecydowal sie nie podnosic cen mimo ogromnych ulepszen -- co jest rzadkoscia w branzy:
- Haiku 4.5: $1/$5 za milion tokenow -- szybka, budzetowa opcja
- Sonnet 4.6: $3/$15 -- najlepszy balans jakosci i ceny (nowy default dla darmowych i Pro uzytkownikow)
- Opus 4.6: $5/$25 -- pelna moc
- Opus 4.6 (powyzej 200K tokenow): $10/$37.50 -- premium tier dla dlugiego kontekstu
Dla porownania, GPT-5.2 kosztuje $2/$10 za milion tokenow -- tanniej, ale na benchmarkach agentowych przegrywa. Gemini 3 Pro ($2 input) balansuje miedzy nimi.
Mozna oszczedzic do 90% dzieki prompt cachingowi i 50% dzieki batch processing -- warto o tym pamietac przy duzych wdrozeniach.
Dostepnosc: Claude API, claude.ai, AWS Bedrock, Google Vertex AI, Microsoft Foundry. Model ID: claude-opus-4-6.
Kogo powinien zainteresowac Opus 4.6?
Podsumowujac -- Claude Opus 4.6 to model, ktory laczy trzy rzeczy, ktorych zadna konkurencja nie oferuje jednoczesnie:
- Milionowy kontekst, ktory naprawde dziala (76% na MRCR v2 vs 18.5% u konkurencji)
- Agent Teams do rownoleglej, autonomicznej pracy nad kodem
- Dominacja w benchmarkach agentowych -- Terminal-Bench, OSWorld, GDPval-AA, Finance Agent
Jesli jestes:
- Developerem -- Agent Teams i 128K output tokenow to game changer dla duzych projektow
- Tech leadem -- autonomiczne agenty zamykajace issues i robiace code review to realna oszczednosc czasu
- CTO/decydentem -- 70% Fortune 100 juz korzysta; pytanie nie brzmi "czy", tylko "kiedy"
- Analitykiem finansowym lub prawnikiem -- Claude w Excelu i PowerPoincie to nowe narzedzia codziennej pracy
Scott White z Anthropic mowi: "Opus 4.6 to model, ktory sprawia, ze przejscie od AI jako gadgetu do AI jako prawdziwego wspolpracownika staje sie konkretne."
Chcesz wdrozyc Claude w swoim zespole lub zautomatyzowac procesy za pomoca agentow AI? Odwiedz aiagents.biz.pl -- pomagamy firmom przejsc od eksperymentow z AI do realnych wdrozen, ktore oszczedzaja czas i pieniadze. Napisz do nas -- porozmawiamy o tym, jak Claude moze pracowac dla Ciebie.
Powiązane artykuły
AI News14 lip 2026
Co oznacza dołączenie Petera Steinbergera do OpenAI dla przyszłości AI?
Analiza wpływu nowego członka zespołu OpenAI na rozwój technologii sztucznej inteligencji.
Czytaj dalejAI News16 cze 2026
AI w medycynie: nowe horyzonty
Rewolucja w diagnostyce i leczeniu dzięki sztucznej inteligencji
Czytaj dalejAI News2 cze 2026
AI w edukacji: Jak sztuczna inteligencja zmienia nauczanie?
Odkryj, jak AI rewolucjonizuje edukację i wpływa na nauczycieli oraz uczniów.
Czytaj dalejAI News5 maj 2026
Jak generatywne AI zmienia oblicze marketingu?
Odkryj, jak generatywne AI rewolucjonizuje kampanie marketingowe i jakie niesie za sobą korzyści oraz wyzwania.
Czytaj dalej