Generowanie obrazow lokalnie: Qwen Image 2512 vs Flux Dev 2 — moj setup i porownanie
Porownanie Qwen Image 2512 i Flux Dev 2 do lokalnej generacji obrazow AI. Setup SwarmUI, multi-model pipeline, LoRA fine-tuning i lekcje z dwoch tygodni testow.
#AI#generowanie obrazow#Qwen Image#Flux#SwarmUI#LoRA#open source#ComfyUI
Przez polrocze placilem OpenAI za kazdy wygenerowany obraz. Miniaturki na YouTube, ilustracje do artykulow, grafiki na social media -- wszystko przechodzilo przez chmure, a rachunki rosly. Postawilem na lokalne generowanie i po dwoch tygodniach intensywnych testow moge powiedziec jedno: nie wroce juz do platnych API. Oto jak wyglada moj setup, co wybralem i dlaczego.

Problem: dlaczego przestalem placic za OpenAI
Moj standardowy workflow wygladal tak: potrzebowalem grafike, wysylalem prompt do gpt-image-1, czekalem na wynik, placilem $0.04-0.08 za kazdy obraz. Przy kilkunastu grafikach tygodniowo kwoty sie sumowaly, ale to nie koszt byl glownym problemem.
Trzy rzeczy mnie frustrowaly najbardziej:
Brak kontroli nad stylem. OpenAI nie pozwala na fine-tuning modelu obrazowego. Nie mialem mozliwosci wytrenowania LoRA na swoich zdjeciach, wiec kazdy portret wygladal jak stock photo -- glupi usmiech, plastikowata cera, zero osobowosci.
Zero prywatnosci. Kazdy prompt i kazdy wynik przechodzi przez serwery OpenAI. Przy generowaniu portretow na baze wlasnych zdjec to jest problem, o ktorym malo kto mowi.
Brak parametrow zaawansowanych. Nie moglem kontrolowac samplera, schedulera, CFG scale, liczby krokow. Dostawalem to, co model dal -- bez mozliwosci iterowania po parametrach.
Potrzebowalem rozwiazania, ktore da mi pelna kontrole, pozwoli na LoRA i bedzie dzialac lokalnie (albo na moim VPS).
Rozwiazanie: SwarmUI + multi-model pipeline
Postawilem na SwarmUI jako centralny backend do generowania grafik. SwarmUI to nowoczesny interfejs do Stable Diffusion, ComfyUI i innych backendow, ktory udzwiga wiele modeli jednoczesnie i wystawia czyste API REST.
Calaosc dziala na GPU VPS (SimplePod) -- placi sie za godzine uzywania, wiec uruchamiam serwer tylko kiedy generuje. Kluczowa decyzja architektoniczna: nie jeden model do wszystkiego, ale pipeline trzech specjalizowanych modeli, kazdy do innego zadania.
Qwen Image 2512 -- krol tekstu w obrazach
Qwen Image 2512 to model 20B parametrow od Alibaby, dostepny na licencji Apache 2.0. To moj "workhorse" -- odpowiada za ilustracje techniczne, infografiki i kazdy obraz, w ktorym pojawia sie tekst.
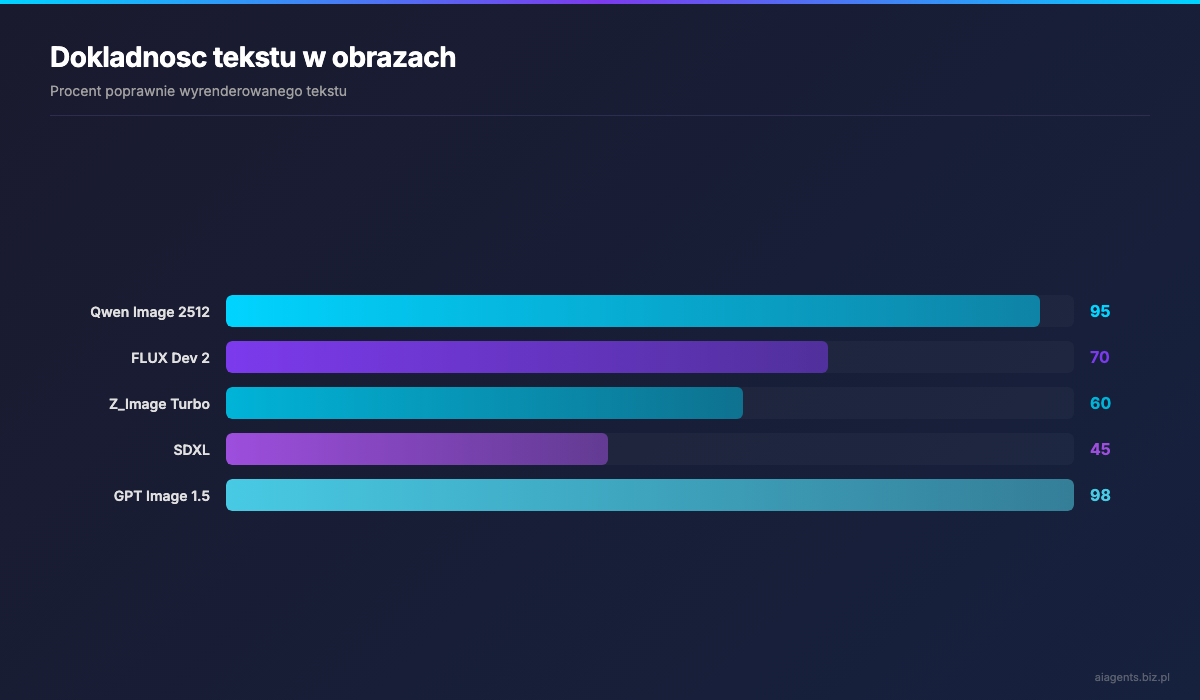
Dlaczego akurat Qwen? Bo generuje tekst w obrazach z 95% dokladnoscia. Zaden inny open-source'owy model nie osiaga takich wynikow. Kiedy potrzebuje diagramu z etykietami albo miniaturki z tytulem -- Qwen daje wynik, ktory da sie uzywac bez recznych poprawek.
Moja konfiguracja Qwen:
QWEN_SAMPLER_PARAMS = {
"sampler": "res_6s_ode",
"scheduler": "beta57",
"sigmashift": 1,
}
# W funkcji generate_image():
gen_params["model"] = "Qwen_Image_2512_BF16.safetensors"
gen_params.update(QWEN_SAMPLER_PARAMS)
gen_params["steps"] = 51
gen_params["cfgscale"] = 3.5
Natywna rozdzielczosc Qwen to 1328x1328 pikseli -- to 68% wiecej pikseli niz standardowe 1024x1024 w modelach FLUX. W praktyce oznacza to ostrzejsze detale, szczegolnie w tekscie i drobnych elementach graficznych.
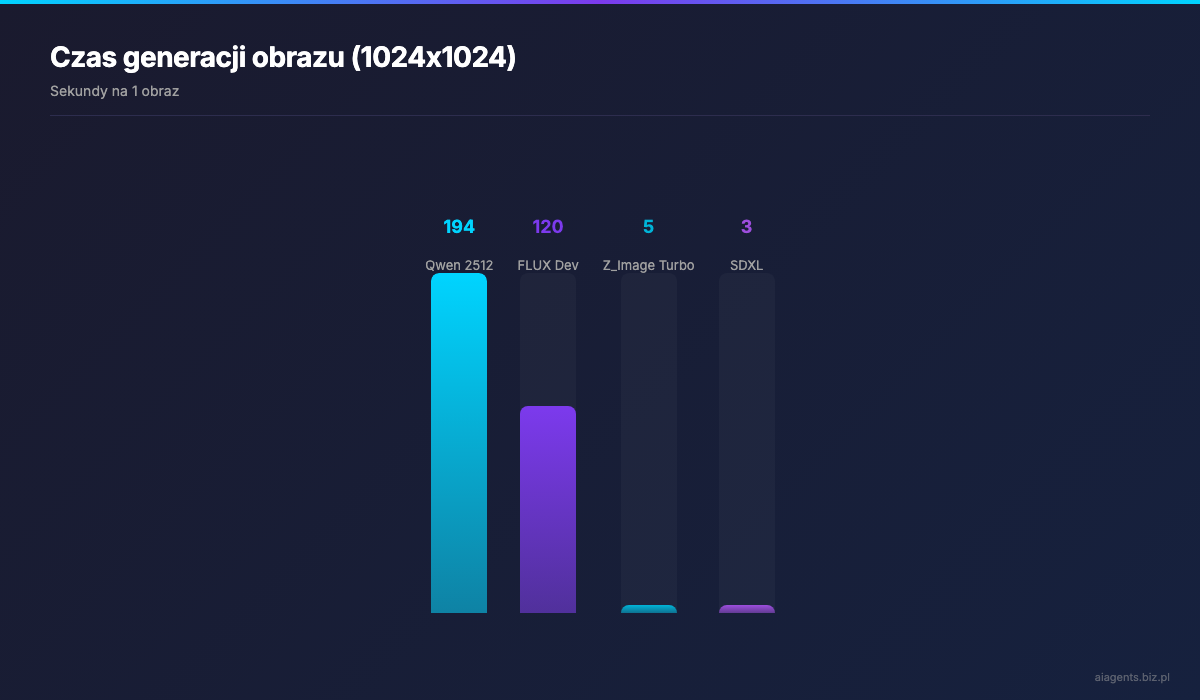
Czas generacji: okolo 194 sekund na obraz przy 51 krokach i rozdzielczosci 1024x1024. To duzo, ale jakosc jest tego warta.
Z_Image Turbo -- portrety w 5 sekund
Do portretow uzywam Z_Image Turbo w polaczeniu z wlasna LoRA wytrenowana na 28 moich zdjeciach. Model generuje obraz w zaledwie 9 krokow -- co przeklada sie na mniej niz 5 sekund na GPU.
Kluczowa konfiguracja:
ZIMAGE_SAMPLER_PARAMS = {
"sampler": "euler",
"scheduler": "beta",
"sigmashift": 7,
}
# Automatyczny wybor modelu:
if model in ("turbo", "zimage"):
gen_params["model"] = "Z_Image_Turbo_BF16.safetensors"
gen_params.update(ZIMAGE_SAMPLER_PARAMS)
gen_params["steps"] = 9
gen_params["cfgscale"] = 1 # KRYTYCZNE -- nie 7!
LoRA "marcin" (trigger word: ohwx man) wytrenowalem przy uzyciu Kohya Musubi Tuner na 28 zdjeciach. Caly trening zajal kilka godzin i potrzebowal zaledwie 6 GB VRAM.
Swiadomie wybralem styl komiksowy zamiast fotorealizmu. Komiksowa stylizacja lepiej ukrywa drobne artefakty AI, ktore przy portretach fotorealistycznych natychmiast wpadaja w "uncanny valley". Efekt jest rozpoznawalny, spojny i -- co wazne -- nie probuje udawac prawdziwego zdjecia.
Wan 2.2 -- wideo AI lokalnie
Trzecim elementem pipeline'u jest Wan 2.2 14B do generowania krotkich klipow wideo. Parametry: 544x960 pikseli, 97 klatek, 24fps -- co daje klipy o dlugosci 4.04 sekundy. Czas generacji to okolo 6 minut na klip.
Uzywam tego do krotkich animacji na social media i intro/outro do filmow na YouTube. Nie zastapi to profesjonalnego wideo, ale na "ozywione ilustracje" sprawdza sie doskonale.
Porownanie: Qwen vs Flux -- co wybrac?
Oto tabelka podsumowujaca moje testy obu modeli:
| Parametr | Qwen Image 2512 | FLUX Dev 2 | |---|---|---| | Rozmiar modelu | 20B | 32B | | Natywna rozdzielczosc | 1328x1328 | 1024x1024 | | Tekst w obrazach | 95% dokladnosc | ~70% dokladnosc | | Fotorealizm | Dobry | Doskonaly (ELO 1149) | | VRAM (BF16) | ~48 GB | ~90 GB | | VRAM (kwantyzacja) | 12-24 GB (FP8/GGUF) | 24-48 GB (FP8) | | Szybkosc (1024x1024) | ~194s / 51 krokow | ~120s / 28 krokow | | Prompt adherence | Bardzo dobry | Dobry | | Licencja | Apache 2.0 | Niekomercyjna | | Najlepszy do | Tekst, infografiki, drafty | Hero images, fotorealizm |
Licencja to decydujacy faktor. Qwen Image 2512 jest na Apache 2.0 -- mozesz uzyc wynikow komercyjnie bez ograniczen. FLUX Dev ma licencje niekomercyjna, co dyskwalifikuje go z wielu zastosowan biznesowych. Nie bez powodu 80% startupow w Bay Area sieglo po chinskie modele open-source.
Moj pipeline w praktyce: Qwen do wszystkiego co zwiazane z tekstem i infografikami, Z_Image Turbo do portretow z LoRA, i ewentualnie FLUX do jednorazowych hero images, gdzie fotorealizm jest kluczowy.
Moja konfiguracja krok po kroku
Caly pipeline jest zintegrowany z moim systemem automatyzacji contentu przez skrypt swarmui_generate.py. Oto jak wyglada typowe uzycie z linii komend:
# Ilustracja techniczna (Qwen, domyslny model)
python swarmui_generate.py \
--prompt "technical diagram showing AI pipeline architecture, labeled nodes" \
--url http://GPU_VPS_IP:7801 \
--output _content-output/2026-02-22-moj-artykul/ \
--name ilustracja_pipeline
# Portret z LoRA (Z_Image Turbo)
python swarmui_generate.py \
--prompt "ohwx man in a modern office, comic book style, professional" \
--model turbo \
--lora marcin \
--url http://GPU_VPS_IP:7801 \
--output _content-output/2026-02-22-moj-artykul/ \
--name portret_autor
Skrypt automatycznie dobiera parametry samplera na podstawie wybranego modelu -- nie trzeba pamietac o roznicach miedzy res_6s_ode a euler:
# Fragment swarmui_generate.py -- automatyczny dobor parametrow
if model in ("turbo", "zimage"):
gen_params["model"] = "Z_Image_Turbo_BF16.safetensors"
gen_params.update(ZIMAGE_SAMPLER_PARAMS)
gen_params["steps"] = 9
gen_params["cfgscale"] = 1
else:
gen_params["model"] = "Qwen_Image_2512_BF16.safetensors"
gen_params.update(QWEN_SAMPLER_PARAMS)
Mapa LoRA jest zdefiniowana centralnie -- wystarczy podac krotka nazwe zamiast pelnej sciezki do pliku:
LORA_MAP = {
"lightning": "Qwen-Image-Lightning-8steps-V2.0",
"marcin": "Quality_1_Training_000003000",
"photo": "Qwen_LoRA_Amateur_Photo_v1",
"skin": "Qwen_LoRA_Skin_Fix_v2",
}
Jedna wazna zasada: tekst na obrazach ZAWSZE dodaje programowo przez Pillow, nigdy przez model. Nawet Qwen z jego 95% dokladnoscia czasem pomyli litere -- a na miniaturce YouTube to nie do przyjecia. Pillow daje 100% kontroli nad fontem, rozmiarem, pozycja i kolorem tekstu.
Lekcje z dwoch tygodni testow
1. CFG Scale = 1 dla Z_Image, nie 7. Przez dwa tygodnie generowalem szum i nie moglem zrozumiec dlaczego Z_Image daje tak fatalne wyniki. Problem? Uzywalem domyslnego CFG=7, podczas gdy ten model wymaga CFG=1. Kazdy model ma swoj "sweet spot" i nie ma jednego zestawu parametrow, ktory dziala wszedzie. To jest najwazniejsza lekcja z calego projektu.
2. Tekst zawsze programowo -- nigdy przez model AI. Nawet najlepszy model (Qwen z 95% accuracy) od czasu do czasu pomyli litere, zle rozmiesci slowa lub wygeneruje tekst w zlym foncie. Pillow/ImageMagick daja stuprocentowa kontrole. Modele AI generuja "wizualna" wersje tekstu, ale nie rozumieja typografii.
3. Styl komiksowy bije fotorealizm w portretach AI. Fotorealistyczne portrety z LoRA wpadaja w "uncanny valley" -- twarz jest prawie dobra, ale cos jest nie tak i widz to czuje. Komiksowa stylizacja eliminuje ten problem calkowicie, bo nikt nie oczekuje perfekcji od rysunku. Bonus: komiksowy styl jest bardziej rozpoznawalny i buduje osobista marke.
4. Maksymalnie 2-3 rownolegle generacje. Qwen na 51 krokach jest wymagajacy. Przy wiecej niz 3 rownoleglych generacjach GPU zaczyna sie przegrzewac, czasy rosna nieliniowo, a czasem generacja po prostu pada. Bezpieczny limit to 2 zadania jednoczesnie.
5. Licencja wazniejsza niz benchmarki. FLUX wygrywa w czystym fotorealizmie (ELO 1149 vs Qwen gdzies okolo 1050), ale jego licencja niekomercyjna uniemozliwia uzycie w wielu projektach. Apache 2.0 od Qwen oznacza, ze moge uzywac wynikow gdziekolwiek, wlacznie z komercyjnymi klientami.
Podsumowanie
Lokalne generowanie obrazow AI w 2026 roku to nie eksperyment -- to dzialajacy pipeline produkcyjny. Moj setup (Qwen Image 2512 + Z_Image Turbo + Wan 2.2) pokrywa 95% moich potrzeb graficznych: od ilustracji technicznych, przez portrety, po krotkie klipy wideo.
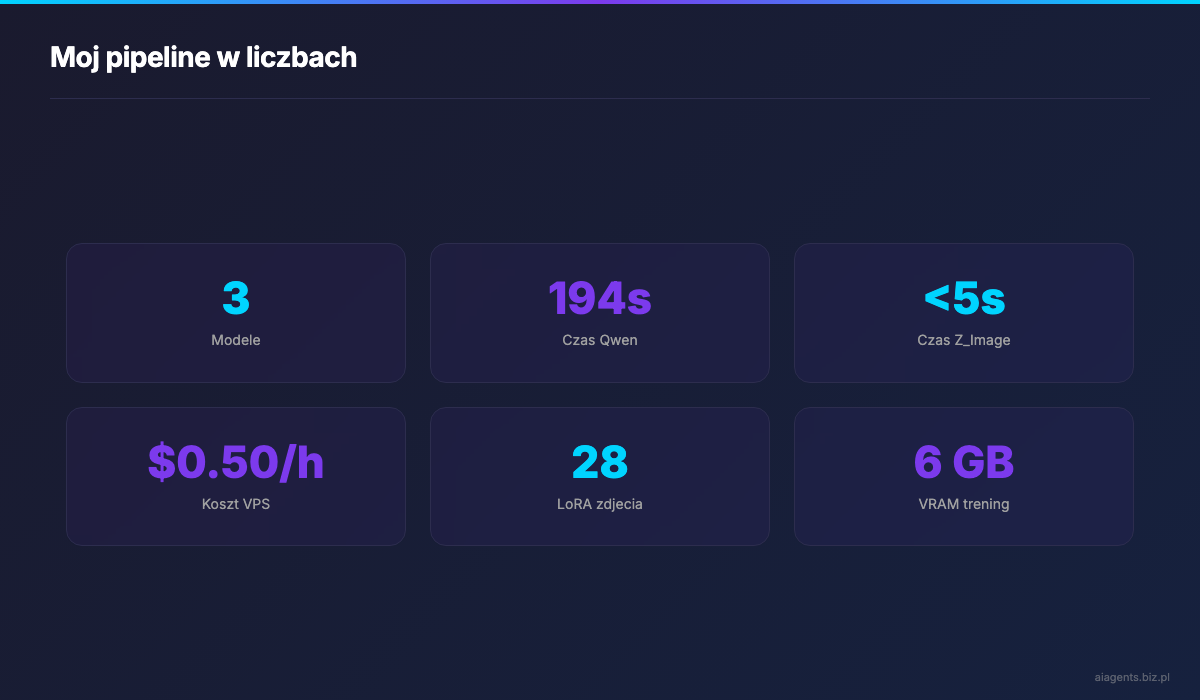
Kluczowe metryki mojego pipeline'u:
- Qwen: 194s/obraz, 95% dokladnosc tekstu, 1328x1328 natywna rozdzielczosc
- Z_Image Turbo: <5s/obraz, portrety z LoRA wytrenowana na 28 zdjeciach
- Koszt: ~$0.50/h VPS vs $0.04-0.08/obraz w OpenAI (breakeven przy ~8-12 obrazach/h)
Jesli generujesz wiecej niz kilkanascie grafik tygodniowo, lokalne modele sie oplaca. A jesli zalezy Ci na kontroli nad stylem, prywatnosci i licencji -- to jedyna sensowna droga.
Kod mojego skryptu integrujacego SwarmUI z automatyzacja contentu jest dostepny w repozytorium projektu. Jesli masz pytania o konfiguracje albo dobor parametrow -- napisz, chetnie pomoge.
Powiązane artykuły
Case Study22 lut 2026
Jak zbudowalem AI Content Hub: z 4-6h recznej pracy do 15 minut z n8n, RAG i Claude Code
Jak zbudowalem AI Content Hub: z 4-6h recznej pracy do 15 minut z n8n, RAG i Claude Code Tworzenie contentu na 7 platform naraz to koszmar logistyczny. Przez miesiace robilem to recznie --- researc...
Czytaj dalejTutorial14 mar 2026
Generowanie obrazow AI w 2026 — Flux, Midjourney, DALL-E i Stable Diffusion
Generowanie obrazow AI w 2026 — Flux, Midjourney, DALL-E i Stable Diffusion
Czytaj dalejCase Study8 mar 2026
Jak zbudowalem AI Content Hub za pomoca Claude Code — Case Study
Jak zbudowalem AI Content Hub za pomoca Claude Code — Case Study
Czytaj dalejCase Study8 mar 2026
Jak zbudowalem AI Content Hub za pomoca Claude Code — Case Study
Jak zbudowalem AI Content Hub za pomoca Claude Code — Case Study
Czytaj dalej