Lokalne modele AI (LLM) w 2026 — Kompletny przewodnik
Kompletny przewodnik po lokalnych modelach AI w 2026 — ranking modeli, narzędzi i wymagań sprzętowych.
#LLM#AI#open-source#Ollama#DeepSeek#GLM#Qwen
Lokalne modele AI (LLM) w 2026 — Kompletny przewodnik
Jeszcze dwa lata temu uruchomienie duzego modelu jezykowego na wlasnym komputerze bylo domena entuzjastow z serwerami za kilkadziesiat tysiecy zlotych. Dzis wystarczy laptop z 16 GB RAM i 30 sekund na instalacje Ollamy, zeby miec lokalne AI dorownujace GPT-4o. To nie marketingowa przesada — to dane z benchmarkow.
W tym przewodniku pokazuje, ktore modele warto uruchomic lokalnie w 2026 roku, na jakim sprzecie, jakimi narzedziami i — co najwazniejsze — dlaczego w ogole warto to robic, skoro API DeepSeek kosztuje zaledwie $0.14 za milion tokenow.

Wielka zmiana: open-source dogania zamkniete modele
Rok 2026 to moment, w ktorym luka miedzy modelami open-source a proprietary praktycznie zniknela. DeepSeek V3.2 z 685 miliardami parametrow dorownuje GPT-5 w matematyce i kodowaniu — a jego trening kosztowal zaledwie 6 milionow dolarow (dla porownania: trening GPT-4 szacowano na ponad 100 milionow). GLM-4.7 osiaga 95.7% na AIME i 73.8% na SWE-bench, co stawia go na rowni z najlepszymi zamknietymi modelami.
Co ciekawe, 7 z 8 najlepszych modeli open-source w 2026 roku pochodzi z Chin. To nie przypadek — chinskie firmy AI, odciete od najnowszych chipow NVIDIA przez sankcje eksportowe, postawily na efektywnosc architektur i otwartosc kodu jako strategie budowania ekosystemu.
Adopcja lokalnych LLM w enterprise rosnie w tempie +240% (2023-2025), a glowne motywacje to nie oszczednosci, lecz prywatnosc danych, zgodnosc z GDPR i HIPAA oraz pelna kontrola nad infrastruktura.
Ranking modeli: co uruchomic lokalnie w 2026
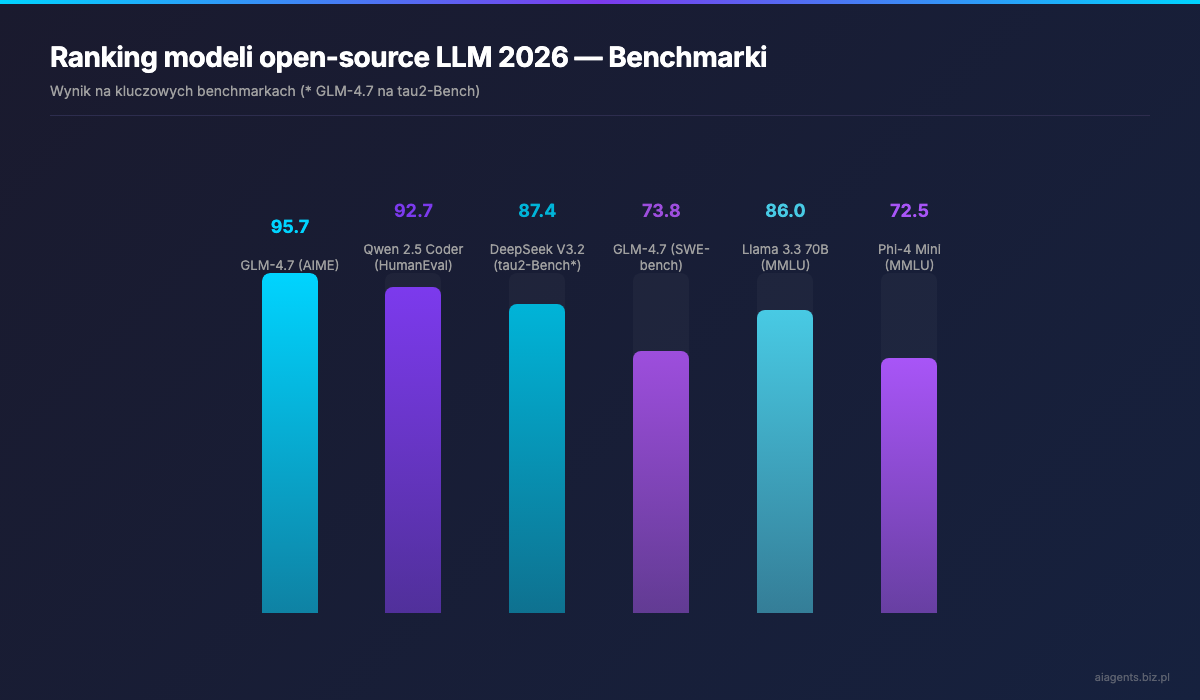
Tier 1: Najlepsze modele na consumer GPU
GLM-4.7 (9B/32B) — najlepszy all-rounder na karty konsumenckie. Model od Zhipu AI z licencja MIT osiaga wyniki, ktore jeszcze rok temu byly zarezerwowane dla GPT-4: AIME 95.7%, SWE-bench 73.8%, tau2-Bench 87.4%. Wersja 9B dziala plynnie na 8 GB VRAM, wersja 32B wymaga 16-24 GB w kwantyzacji Q4.
Qwen 2.5 Coder 32B — "GPT-4o killer" w kodowaniu. HumanEval 92.7% mowi sam za siebie. Miesci sie na RTX 3090 lub 4090 w kwantyzacji Q4_K_M i generuje kod na poziomie, ktory rok temu byl domena wylacznie Claude i GPT-4. Idealny do pair-programmingu, code review i automatyzacji zadan deweloperskich.
Llama 3.3 70B — Meta nadal dostarcza solidne modele ogolnego przeznaczenia. Wersja 70B w kwantyzacji Q4 wymaga ~40 GB RAM, co czyni ja idealnym kandydatem na Apple Silicon z 48 GB unified memory lub setup z dwoma GPU.
Tier 2: Modele-giganty (zaawansowany sprzet)
DeepSeek V3.2 (685B MoE) — architektura Mixture of Experts to przelomu 2026 roku. Model ma 685 miliardow parametrow, ale dzieki MoE aktywuje w danym momencie tylko 37B — co oznacza, ze wymaga znacznie mniej VRAM niz sugerowaloby jego rozmiary. Nadal potrzebuje jednak minimum 2x RTX 4090 lub dedykowanego serwera.
DeepSeek V4 (nadchodzi Q1-Q2 2026) — zapowiedziany nastepca z 1 bilionem parametrow, projektowany specjalnie pod dual RTX 4090 lub single RTX 5090. Jesli obietnicy dotrzymaja, bedzie to pierwszy model klasy frontier, ktory mozna uruchomic na sprzecie za okolo 15 000 zl.
Tier 3: Male, szybkie, wyspecjalizowane
Phi-4 Mini (3.8B) od Microsoftu — zaskakujaco dobry w rozumowaniu jak na swoj rozmiar. Dziala na telefonach i Raspberry Pi. Idealny do edge computing i aplikacji offline.
Mistral Small 3.1 (24B) — wielojezyczny model z 128K kontekstem. Dobry do analizy dlugich dokumentow i tlumaczen.
Architektura MoE: dlaczego modele 685B dzialaja na domowym GPU
Mixture of Experts to architektura, ktora rewolucjonizuje wymagania sprzetowe w 2026. Zamiast aktywowac wszystkie parametry przy kazdym tokenie, model kieruje dane tylko do wybranych "ekspertow" — wyspecjalizowanych podsieci.
W praktyce oznacza to, ze DeepSeek V3.2 z 685B parametrami aktywuje przy kazdym zapytaniu tylko 37B (5.4%), a mniejsze modele MoE z 400B parametrami moga aktywowac zaledwie 10B. To zmniejsza wymagania dotyczace VRAM i mocy obliczeniowej o rzad wielkosci w porownaniu z tradycyjnymi architekturami dense.
Narzedzia: jak uruchomic LLM lokalnie
Ollama — de facto standard (wspomniana w 24 z 29 analizowanych artykulow)
Ollama to CLI tool, ktory zrobil dla lokalnych LLM to, co Docker zrobil dla konteneryzacji — abstrakcje skomplikowanego procesu do jednej komendy. Instalacja trwa 30 sekund, a uruchomienie modelu — kolejne 30.
LM Studio — najlepszy GUI
Dla tych, ktorzy wola interfejs graficzny, LM Studio oferuje pelne srodowisko do eksperymentowania z modelami: przegladanie dostepnych modeli, sciganie ich jednym kliknieciem, konfiguracja parametrow i czat. Wbudowany serwer API kompatybilny z OpenAI pozwala uzyc LM Studio jako drop-in replacement dla GPT w istniejacych aplikacjach.
vLLM — produkcja (2-4x throughput)
Jesli potrzebujesz obsluzyc wielu uzytkownikow jednoczesnie, vLLM oferuje 2-4x wiekszy throughput niz Ollama dzieki technikom takim jak PagedAttention i continuous batching. To standard dla deploymentu produkcyjnego.
Inne warte uwagi
- llama.cpp — niskopoziomowa biblioteka C++, na ktorej bazuja Ollama i LM Studio. Dla tych, ktorzy chca maksymalnej kontroli.
- Jan — open-source alternatywa dla LM Studio, offline-first.
- text-generation-webui (oobabooga) — rozbudowany interfejs z pluginami.
Wymagania sprzetowe: ile VRAM potrzebujesz?
GPU NVIDIA
RTX 4090 (24 GB VRAM) to sweet spot 2026 roku. Pozwala uruchomic modele do ~45B parametrow w pelnej precyzji lub modele 70B w kwantyzacji Q4. Cena na rynku wtornym spadla do okolo 6000-7000 zl.
RTX 5090 (32 GB VRAM) zmienia zasady gry — dodatkowe 8 GB otwiera drzwi do modeli, ktore wczesniej wymagaly dwoch kart. DeepSeek V4 jest projektowany z mysla wlasnie o tej karcie.
RTX 3090 (24 GB) — nadal doskonaly wybor budzetowy. Na rynku wtornym za 2500-3500 zl daje te same 24 GB VRAM co RTX 4090.
Apple Silicon
Mac z M2 Pro/Max/Ultra i 32-48 GB unified memory to realna alternatywa dla GPU NVIDIA. Unified memory oznacza, ze cala pamiec jest dostepna dla modelu (bez podzialu na RAM i VRAM). M2 Ultra z 192 GB unified memory moze uruchomic modele 70B w pelnej precyzji.
Wadla: wolniejsze generowanie tokenow niz na GPU NVIDIA (MLX vs CUDA). Zaleta: cisza, niskie zuzycie energii, brak konfiguracji sterownikow.
Kwantyzacja: magiczna sztuczka
Kwantyzacja Q4_K_M redukuje zuzycie VRAM o 50-75% przy zaledwie ~2% utracie jakosci. W praktyce oznacza to, ze model 70B, ktory normalnie wymaga 140 GB RAM w FP16, mozna uruchomic w 35-40 GB po kwantyzacji do 4-bit. To wlasnie dlatego RTX 4090 z 24 GB VRAM moze obslugiwac modele, ktore teoretycznie powinny wymagac 3-4 razy wiecej pamieci.
Tutorial: Twoj pierwszy lokalny LLM w 5 minut
Krok 1: Instalacja Ollamy
Na macOS i Linux:
curl -fsSL https://ollama.ai/install.sh | sh
Na Windows: pobierz instalator ze strony ollama.ai.
Krok 2: Uruchomienie modelu
# GLM-4.7 9B — najlepszy all-rounder
ollama run glm4:9b
# Qwen 2.5 Coder 32B — do kodowania (wymaga 24 GB VRAM)
ollama run qwen2.5-coder:32b
# Phi-4 Mini — lekki, na slabszy sprzet
ollama run phi4-mini
Ollama automatycznie pobiera model przy pierwszym uruchomieniu. GLM-4.7 9B w kwantyzacji Q4 wazy okolo 5 GB.
Krok 3: Uzycie jako API (kompatybilne z OpenAI)
curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "glm4:9b",
"messages": [{"role": "user", "content": "Wyjasnij MoE w 3 zdaniach"}]
}'
Mozesz uzyc tego endpointu w kazdej aplikacji, ktora obsluguje OpenAI API — wystarczy zmienic base URL na http://localhost:11434/v1.
Krok 4: Integracja z kodem (Python)
from openai import OpenAI
client = OpenAI(base_url="http://localhost:11434/v1", api_key="ollama")
response = client.chat.completions.create(
model="glm4:9b",
messages=[{"role": "user", "content": "Napisz funkcje sortujaca w Pythonie"}]
)
print(response.choices[0].message.content)
Bezpieczenstwo: slowo ostrzezenia
Lokalny LLM nie jest automatycznie bezpieczny. Badania z 2025/2026 pokazuja, ze w internecie jest 42 665 eksponowanych instancji AI agents (dane Shodan), z czego 93.4% ma mozliwe do obejscia mechanizmy autentykacji.
Jesli uruchamiasz lokalne API:
- Nie wystawiaj portu 11434 na zewnatrz bez VPN lub reverse proxy z autentykacja
- Uzyj bindowania do localhost (
OLLAMA_HOST=127.0.0.1) - Szyfruj dysk z modelami i danymi konwersacji
- Monitoruj zapytania — nawet lokalny model moze byc wektorem ataku, jesli akceptuje dane z zewnatrz
Kiedy lokalnie, a kiedy API?
Lokalne LLM w 2026 to nie kwestia oszczednosci. Przy cenie API DeepSeek $0.14 za milion tokenow, nawet intensywne uzycie kosztuje grosze. Powody, dla ktorych warto uruchamiac modele lokalnie, to:
- Prywatnosc — dane nigdy nie opuszczaja Twojego komputera (GDPR, HIPAA, tajemnice firmowe)
- Latencja — zero round-trip do serwera, idealne do IDE i narzedzi real-time
- Dostepnosc — dziala offline, w samolocie, w strefie bez internetu
- Customizacja — fine-tuning na wlasnych danych, LoRA adaptery, system prompty bez ograniczen
- Brak limitow — zadnych rate limits, zadnych kosztow per-token przy duzym wolumenie
Podsumowanie
Rok 2026 to punkt przelomu dla lokalnych LLM. Modele open-source osiagnely poziom, ktory jeszcze dwa lata temu byl zarezerwowany dla GPT-4 i Claude. Architektura MoE sprawia, ze modele z setkami miliardow parametrow mozna uruchomic na sprzetcie za kilka tysiecy zlotych. A narzedzia takie jak Ollama zredukowaly bariere wejscia do jednej komendy w terminalu.
Jesli jeszcze nie uruchomiles lokalnego LLM — teraz jest najlepszy moment. Zainstaluj Ollamee, pobierz GLM-4.7 9B i przekonaj sie sam. Caly proces zajmie Ci mniej czasu niz przeczytanie tego artykulu.
Powiązane artykuły
AI News22 lut 2026
Nowości AI 2026 - nowe modele, agenty i rewolucja open-source
Nowości AI 2026 - nowe modele, agenty i rewolucja open-source W ciągu ostatnich trzech miesięcy branża AI wypuściła więcej przełomowych modeli niż przez cały 2024 rok. Rynek agentów AI przekroczył ...
Czytaj dalejTutorial14 mar 2026
Generowanie obrazow AI w 2026 — Flux, Midjourney, DALL-E i Stable Diffusion
Generowanie obrazow AI w 2026 — Flux, Midjourney, DALL-E i Stable Diffusion
Czytaj dalejTutorial14 mar 2026
AI Agent Frameworks 2026 — Kompletny przewodnik po frameworkach do budowania agentow AI
AI Agent Frameworks 2026 — Kompletny przewodnik po frameworkach do budowania agentow AI
Czytaj dalejTutorial14 mar 2026
Integracja AI z IoT: Tworzenie Inteligentnych Systemów Domowych Jutra
Integracja AI z IoT: Tworzenie Inteligentnych Systemów Domowych Jutra
Czytaj dalej