Claude Opus 4.6: benchmarki, milion tokenow i agenci AI
Claude Opus 4.6 od Anthropic zmienia zasady gry: milion tokenow kontekstu, Agent Teams i najlepsze wyniki w benchmarkach agentowych. Sprawdz twarde dane.
#Claude#Anthropic#AI#benchmarki#Claude Code#agenci AI#LLM
W lutym 2026 roku Anthropic zaprezentowalo swoj najnowszy model AI, ktory fundamentalnie zmienia sposob, w jaki programisci i firmy korzystaja ze sztucznej inteligencji. Claude Opus 4.6 to nie tylko kolejna aktualizacja -- to przelamanie bariery miedzy asystentem a autonomicznym agentem, zdolnym do samodzielnego prowadzenia zlozonych projektow programistycznych. Czy nowy model faktycznie jest tak dobry, jak obiecuje Anthropic? Sprawdzamy twarde dane.
Rewolucja w kontekscie: milion tokenow na wyciagniecie reki
Jedna z najbardziej przelomowych zmian w Claude Opus 4.6 to okno kontekstowe siagajace miliona tokenow. To odpowiednik okolo 750 powiesci albo calego kodu zrodlowego duzej aplikacji enterprise. Dla programistow oznacza to mozliwosc analizy pelnego repozytorium kodu w jednym zapytaniu, bez koniecznosci dzielenia go na fragmenty.
Dotychczas Claude Opus 4.5 oferowat 200 tysiecy tokenow, co juz bylo imponujace. Skok do miliona tokenow stawia Claude'a na rowni z Gemini 3 Pro od Google, a daleko przed GPT-5.2 od OpenAI, ktory wciaz operuje na 128 tysiacach tokenow kontekstu.
Co wazne, te dodatkowe tokeny nie sa "martwe". Na benchmarku MRCR v2, ktory testuje odnajdywanie informacji w dlugim kontekscie, Opus 4.6 osiagnal 76% skutecznosci na wariancie z 8 igielkami w milionie tokenow. Dla porownania, Sonnet 4.5 osiagnal zaledwie 18.5% na tym samym tescie. To ponad czterokrotna poprawa.
Benchmarki: twarde liczby mowia same za siebie
Opus 4.6 dominuje w niemal kazdym kluczowym benchmarku, szczegolnie w zadaniach agentowych i programistycznych.
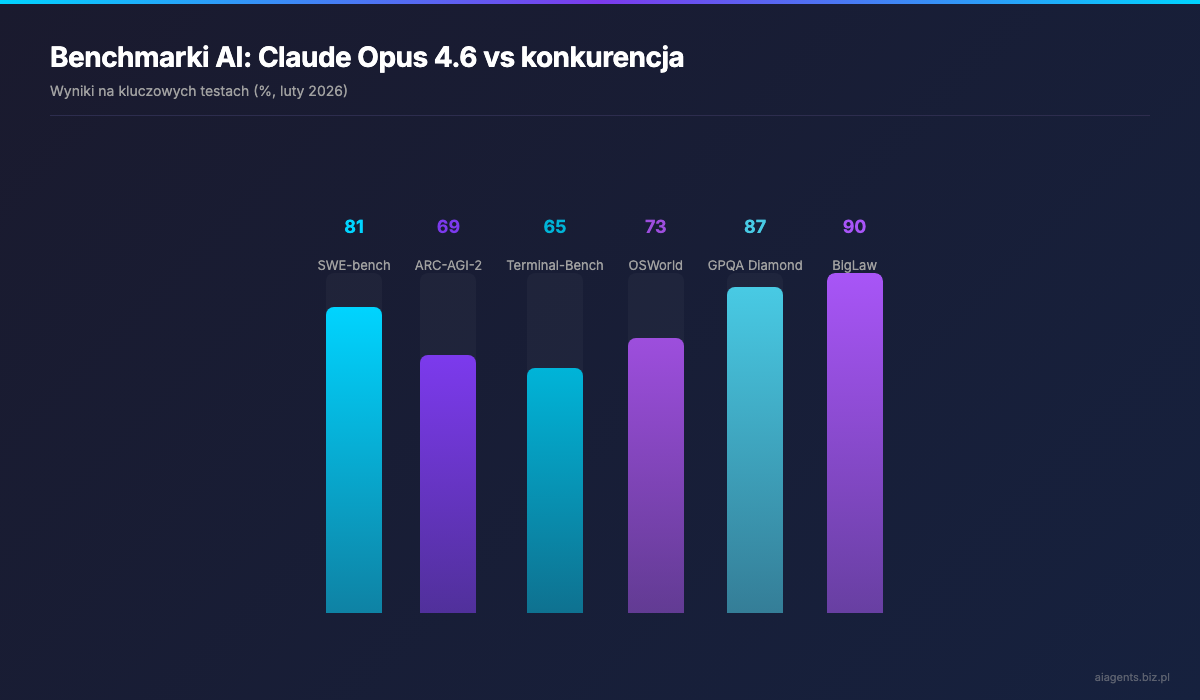
Na SWE-bench Verified, zlotym standardzie testowania umiejetnosci programistycznych, model osiagnal 81.4% (z modyfikacja promptu). Na ARC-AGI-2, tescie abstrakcyjnego rozumowania, Claude Opus 4.6 zdobyl 68.8% -- to dramatyczny skok z 37.6% w wersji 4.5 i wynik znacznie lepszy niz GPT-5.2 (54.2%) czy Gemini 3 Pro (45.1%).
Agentic coding -- nowa kategoria dominacji
Szczegolnie imponujace sa wyniki w zadaniach agentowych:
- Terminal-Bench 2.0: 65.4% -- najlepszy wynik w branzy
- OSWorld (autonomiczne uzycie komputera): 72.7%
- MCP Atlas (skalowalne uzycie narzedzi): 62.7% na wysokim wysilku
- BigLaw Bench (rozumowanie prawnicze): 90.2% -- najwyzszy wynik sposrod wszystkich modeli Claude
Na benchmarku GDPval-AA, ktory mierzy profesjonalna prace z wiedza, Opus 4.6 uzyskal wynik o 144 punkty Elo wyzszy niz GPT-5.2 i o 190 punktow lepszy niz poprzednia wersja Opus 4.5.
Claude vs konkurencja: jak wypada porownanie?
Rynek modeli AI w 2026 roku jest bardziej konkurencyjny niz kiedykolwiek. Jak Claude Opus 4.6 wypada na tle GPT-5.2 i Gemini 3 Pro?
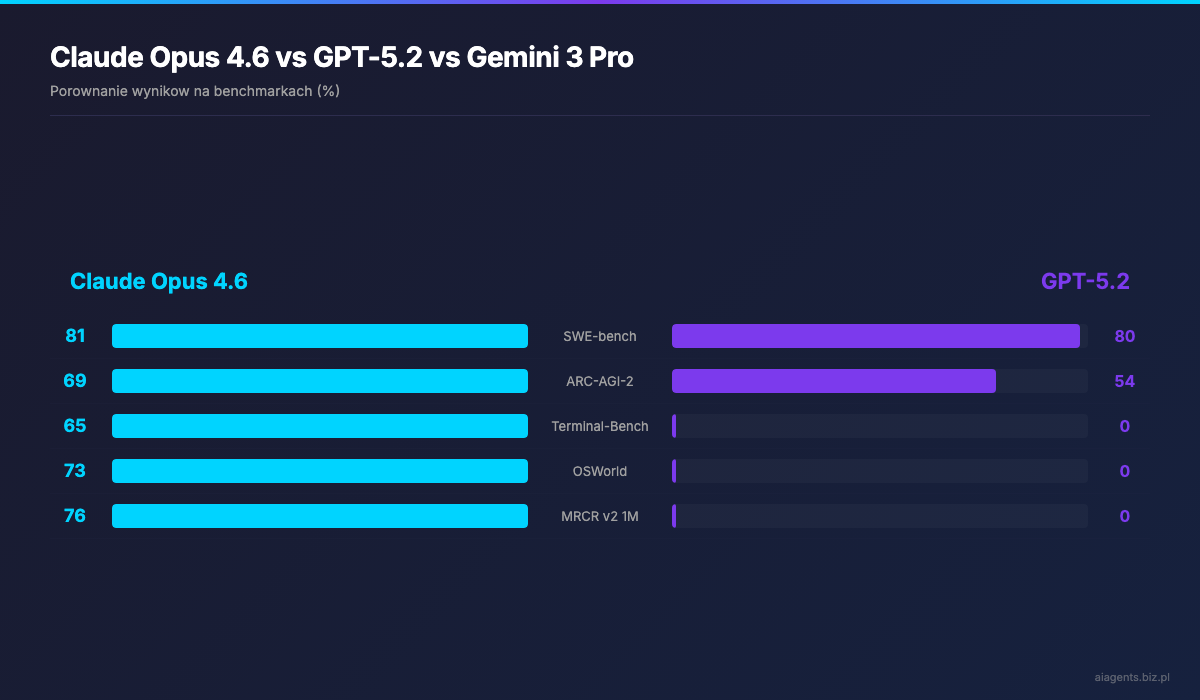
| Metryka | Claude Opus 4.6 | GPT-5.2 | Gemini 3 Pro | |---------|-----------------|---------|--------------| | SWE-bench Verified | 81.4% | 80.0% | 76.2% | | ARC-AGI-2 | 68.8% | 54.2% | 45.1% | | Okno kontekstu | 1M tokenow | 128K | 1M | | Cena (input/1M) | $5 | $1.75 | $2 |
Claude wygrawa w rozumowaniu i zadaniach agentowych, GPT-5.2 oferuje nizsza cene, a Gemini 3 Pro balansuje miedzy nimi z pelnym multimodalnym wsparciem. Kluczowa roznica: Claude jest jedynym modelem, ktory laczy milionowy kontekst z dominacja w benchmarkach agentowych.
Agent Teams: przyszlosc autonomicznego kodowania
Najbardziej ekscytujaca nowoscia w ekosystemie Claude jest funkcja Agent Teams (dostepna w research preview). Zamiast jednego agenta AI, uzytkownicy Claude Code moga uruchomic zespoly rownoleglych agentow, z ktorych kazdy pracuje na osobnej galezi git (worktree).

Jak to dziala w praktyce? Wyobrazmy sobie refaktoring duzej aplikacji:
- Agent 1 analizuje backend i proponuje zmiany w API
- Agent 2 aktualizuje testy jednostkowe
- Agent 3 przeszukuje dokumentacje i przygotowuje changelog
- Agent 4 sprawdza zgodnosc z wytycznymi bezpieczenstwa
Wszystko odbywa sie rownolegle, a programista moze przejmowac kontrole nad dowolnym agentem w czasie rzeczywistym (Shift+Up/Down lub tmux). To fundamentalna zmiana -- przejscie od "AI jako asystent" do "AI jako zespol".
Dodatkowo, nowa funkcja Context Compaction automatycznie podsumowuje stary kontekst, umozliwiajac agentom prace przez nieograniczony czas bez utraty waznych informacji.
Bezpieczenstwo: 500 luk zero-day znalezionych przed premiera
Anthropic stawia na bezpieczenstwo jak zaden inny dostawca modeli AI. Przed premiera Opus 4.6 przeprowadzono najobszerniejszy zestaw testow bezpieczenstwa w historii firmy, wlaczajac 6 nowych sond cyberbezpieczenstwa opracowanych specjalnie na te okazje.
Wynik? Model odkryl ponad 500 wczesniej nieznanych luk zero-day w otwartym kodzie zrodlowym. Ta sama zdolnosc jest teraz dostepna dla obroncow -- Claude Code Security pozwala zespolom skanowac bazy kodu i sugerowac poprawki bezpieczenstwa, ktore tradycyjne metody czesto pomijaja.
Na benchmarku CyberGym Claude znajduje rzeczywiste luki lepiej niz jakikolwiek inny model. Wskaznik niebezpiecznych zachowan pozostaje niski -- na poziomie najlepiej wyrownanych modeli w branzy -- przy jednoczesnym najnizszym wskazniku nadmiernej odmowy (over-refusal).
Enterprise w liczbach: 70% Fortune 100 juz korzysta
Adopcja Claude w srodowisku korporacyjnym jest imponujaca:
- 30 milionow aktywnych uzytkownikow miesiecznie
- 70% firm z listy Fortune 100 korzysta z Claude
- 29% udzialu w rynku asystentow AI dla firm
- Cognizant wyposazyl 350 000 pracownikow w Claude
- 92% wskaznik satysfakcji wsrod uzytkownikow
- 2-10x przyspieszenie procesow developerskich
Dla programistow szczegolnie istotny jest wskaznik adopcji -- wedlug raportu Faros AI z 2026 roku, 41-68% developerow korzysta z Claude lub Claude Code w codziennej pracy.
Cennik i dostepnosc: bez niespodzianek
Anthropic zdecydowal sie nie podnosic cen mimo znaczacych ulepszen:
- Haiku 4.5: $1/$5 za milion tokenow -- najszybsza, budzetowa opcja
- Sonnet 4.6: $3/$15 za milion tokenow -- najlepszy balans jakosci i ceny
- Opus 4.6: $5/$25 za milion tokenow -- pelna moc
- Opus 4.6 (200K+ tokenow): $10/$37.50 -- premium tier dla dlugiego kontekstu
Sonnet 4.6, ktory zastapil Sonnet 4.5 jako domyslny model dla darmowych i Pro uzytkownikow, oferuje wydajnosc porownywalna z tym, co wczesniej wymagalo Opusa -- za ulamek ceny.
Podsumowanie: czy warto przesiasc sie na Claude?
Claude Opus 4.6 to obecnie najbardziej zdolny model do zadan agentowych i programistycznych na rynku. Milionowe okno kontekstu, Agent Teams i dominacja w benchmarkach rozumowania czynia go naturalnym wyborem dla zespolow developerskich i firm, ktore chca wdrazac autonomiczna automatyzacje.
Jesli Twoja firma rozważa wdrozenie agentow AI, automatyzacje procesow lub chce przyspieszyc development -- warto przyjrzec sie ekosystemowi Claude blizej. W AI Agents pomagamy firmom wdrazac te rozwiazania w praktyce.
Chcesz dowiedziec sie wiecej o wdrazaniu Claude w Twoim zespole? Skontaktuj sie z nami przez aiagents.biz.pl -- porozmawiamy o mozliwosciach automatyzacji dopasowanych do Twojego biznesu.
Powiązane artykuły
AI News22 lut 2026
Gemini 3.1 Pro — Google za $2 pokonuje modele za $75. Ale nie we wszystkim
Google Gemini 3.1 Pro podwoil wynik rozumowania i kosztuje 7.5x mniej niz Claude Opus 4.6. Pelne porownanie z liczbami i tabelami.
Czytaj dalejAI News22 lut 2026
Gemini 3.1 Pro — Google za $2 pokonuje modele za $75. Ale nie we wszystkim
Google Gemini 3.1 Pro podwoil wynik rozumowania i kosztuje 7.5x mniej niz Claude Opus 4.6. Pelne porownanie z liczbami i tabelami.
Czytaj dalejAI News22 lut 2026
Gemini 3.1 Pro — Google za $2 pokonuje modele za $75. Ale nie we wszystkim
Model za 2 dolary, ktory pokonuje flagowce kosztujace 7.5x wiecej. ARC-AGI-2: 77.1% vs 68.8% Claude. Ale GDPval-AA i Terminal-Bench mowia inna historie.
Czytaj dalejAI News22 lut 2026
Nowości AI 2026 - nowe modele, agenty i rewolucja open-source
Nowości AI 2026 - nowe modele, agenty i rewolucja open-source W ciągu ostatnich trzech miesięcy branża AI wypuściła więcej przełomowych modeli niż przez cały 2024 rok. Rynek agentów AI przekroczył ...
Czytaj dalej