Gemini 3.1 Pro — Google za $2 pokonuje modele za $75. Ale nie we wszystkim
Google Gemini 3.1 Pro podwoil wynik rozumowania i kosztuje 7.5x mniej niz Claude Opus 4.6. Pelne porownanie z liczbami i tabelami.
#Gemini#Google AI#Claude#GPT#benchmark#LLM
Model za 2 dolary na wejsciu, ktory pokonuje flagowce kosztujace 10-37 razy wiecej. Google Gemini 3.1 Pro, wydany 19 lutego 2026, podwoil wynik w ARC-AGI-2 wzgledem poprzednika — z 31.1% do 77.1%. Dla porownania: Claude Opus 4.6 osiaga 68.8%, a GPT-5.2 zaledwie 52.9%. I to wszystko przy cenie $2 za milion tokenow wejsciowych, podczas gdy Opus kosztuje $15, a GPT okolo $10.
Brzmi jak koniec wyścigu? Nie tak szybko. Benchmarki to nie calość obrazu, a w kilku kluczowych kategoriach Google nadal traci. Oto pelna analiza — z liczbami, tabelami i uczciwa ocena, kto naprawde prowadzi w lutym 2026.

Co nowego w Gemini 3.1 Pro
Gemini 3.1 Pro to pierwszy model Google z numeracją ".1" zamiast dotychczasowej ".5". Zmiana nie jest kosmetyczna — sygnalizuje przyspieszony cykl wydawniczy. Google skraca dystans miedzy duzymi premierami, odpowiadajac na agresywne tempo Anthropic i OpenAI.
Deep Think Mini — trzy poziomy rozumowania
Najwazniejsza nowość to trzy poziomy rozumowania (thinking levels): low, medium i high. Google nazywa to "Deep Think Mini" — technologia, ktora debiutowala w Gemini 3 Deep Think jako funkcja zarezerwowana wylacznie dla modelu Ultra, teraz trafia do modelu Pro.
W praktyce oznacza to, ze developer moze dostosowac glebokosc rozumowania do zadania:
- Low — szybkie odpowiedzi, minimalne rozumowanie, najnizsza latencja
- Medium — balans miedzy jakoscia a szybkoscia
- High — pelne lancuchy rozumowania, porownywalne z modelami "reasoning"
To wazna zmiana architektoniczna. Zamiast osobnych modeli do roznych zadan (jak to robi OpenAI z o1/o3 vs GPT), Google daje jeden model z regulowanym poziomem.
Multimodalność i SVG
Gemini 3.1 Pro pozostaje modelem multimodalnym — przyjmuje tekst, obrazy, audio i wideo. Nowa funkcja to generowanie animowanych SVG z tekstu — model potrafi stworzyc wektorowa grafike z opisem, co otwiera ciekawe mozliwosci dla prototypowania interfejsow i wizualizacji.
Kontekst i przepustowosc
Okno kontekstowe to 1 milion tokenow — 5 razy wiecej niz 200K oferowane przez Claude i GPT. Maksymalny output to 64K tokenow. Przepustowosc API to 10 miliardow tokenow na minute, co pozwala na skalowanie produkcyjne nawet dla bardzo duzych wdrozen.
Platformy i dostepnosc
Model jest dostepny na wielu platformach:
- Gemini App (750+ milionow aktywnych uzytkownikow miesieczne)
- AI Studio i Vertex AI (dla developerow i firm)
- NotebookLM (praca z dokumentami)
- GitHub Copilot (integracja z IDE)
- Dedykowane CLI do uzycia z terminala
Benchmarki — pelna tabela porownawcza
Ponizej zestawienie wynikow Gemini 3.1 Pro, Claude Opus 4.6 i GPT-5.2/5.3 w najwazniejszych benchmarkach. Najlepszy wynik w kazdej kategorii jest oznaczony pogrubieniem.
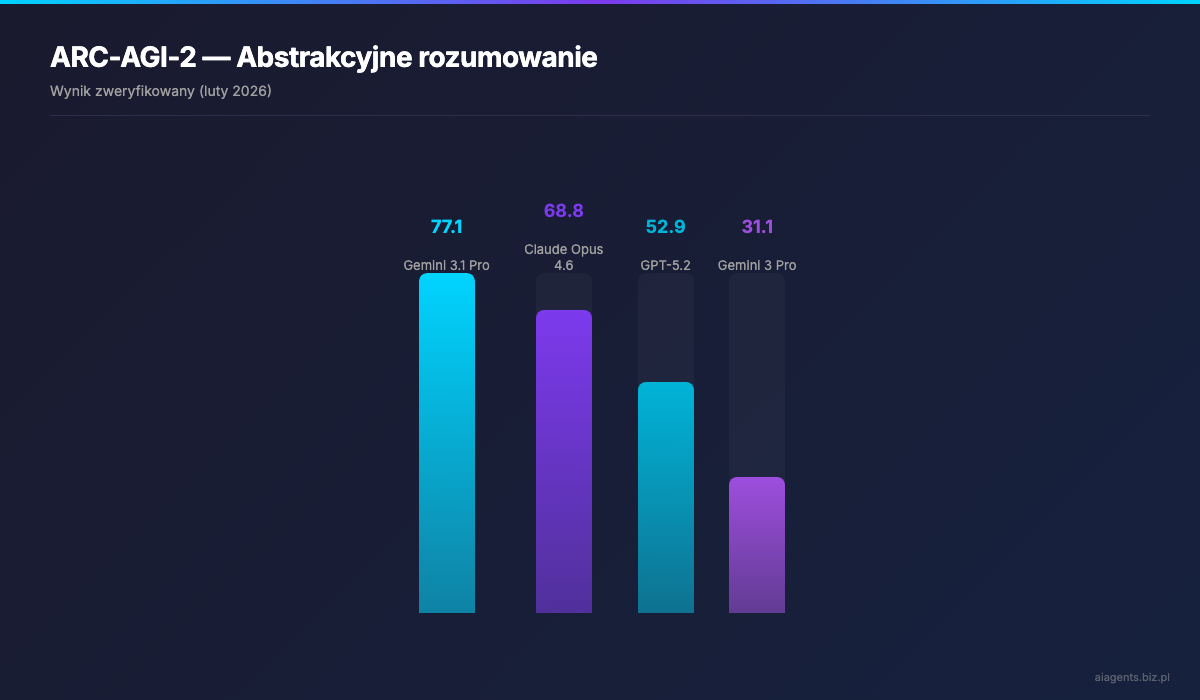
Rozumowanie i wiedza
Progres wzgledem Gemini 3 Pro
Warto spojrzec na skok jakosciowy wzgledem poprzednika:
- ARC-AGI-2: 31.1% → 77.1% (wzrost o 148%)
- MCP Atlas: 54.1% → 69.2% (wzrost o 28%)
- BrowseComp: 59.2% → 85.9% (wzrost o 45%)
To nie jest inkrementalny update. To fundamentalna zmiana w zdolnosciach rozumowania — prawdopodobnie efekt integracji technologii Deep Think.
Gdzie Gemini 3.1 Pro wygrywa
Abstrakcyjne rozumowanie
ARC-AGI-2 to benchmark zaprojektowany specjalnie do mierzenia abstrakcyjnego rozumowania — zdolnosci, ktora wielu badaczy uwaza za kluczowa na drodze do AGI. Gemini 3.1 Pro z wynikiem 77.1% wyprzedza Opus o 8.3 punktu procentowego, a GPT o 24.2 punktu. To zdecydowane prowadzenie.
Wiedza ekspercka
W GPQA Diamond (pytania na poziomie doktoratu z fizyki, chemii i biologii) Gemini osiaga 94.3% — najwyzszy wynik wsrod trzech modeli. Roznica wynosi 1.9 punktu wzgledem GPT i 3 punkty wzgledem Opus.
Zadania agentowe
APEX-Agents mierzy zdolnosc modelu do wykonywania zlozonych, wieloetapowych zadan z autonomia. Gemini z 33.5% prowadzi przed Opus (29.8%) i GPT (23.0%). MCP Atlas — benchmark orchestracji narzedzi — potwierdza te przewage: 69.2% vs 54.1% poprzednika.
Kontekst 1M tokenow
Milion tokenow kontekstu to nie tylko wieksza liczba — to jakosciowa roznica w typie zadan, ktore mozna zlecic modelowi. Analiza calych repozytoriow kodu, dlugich dokumentow prawnych czy transkrypcji wielogodzinnych spotkan — to scenariusze, w ktorych 200K po prostu nie wystarczy.
Wyszukiwanie informacji
BrowseComp z wynikiem 85.9% (vs 59.2% poprzednika) sugeruje, ze Gemini 3.1 Pro znaczaco poprawil zdolnosc przeszukiwania i syntezy informacji z internetu.
Gdzie Claude i GPT nadal wygrywaja
Preferencje uzytkownikow — GDPval-AA
To prawdopodobnie najwazniejszy benchmark, o ktorym Google nie mowi glosno. GDPval-AA Elo mierzy, jak ludzie oceniaja odpowiedzi modeli w slepym teście. Sonnet 4.6 (1633 Elo) i Opus 4.6 (1606 Elo) zdecydowanie prowadza nad Gemini (1317 Elo). Roznica 316 punktow Elo to przepasc — oznacza, ze w bezposrednim porownaniu uzytkownicy zdecydowanie wola odpowiedzi Claude.
To wazne, bo benchmarki mierza zdolnosci techniczne, ale GDPval mierzy cos innego — jakosc komunikacji, uzytecznosc odpowiedzi, zgodnosc z intencja uzytkownika. I tutaj Claude utrzymuje wyrazna przewage.
Zaawansowane kodowanie — Terminal-Bench i SWE-Bench Pro
W Terminal-Bench 2.0 (operacje terminalowe, skrypty, automatyzacja) GPT-5.3-Codex dominuje z 77.3%, Gemini osiaga 68.5%, a Sonnet 59.0%. W SWE-Bench Pro wynik to GPT 56.8% vs Gemini 54.2%. Dla zespolow inzynieryjnych, ktore polegaja na modelu do codziennej pracy z kodem, te roznice maja znaczenie.
Tool use z rozumowaniem — HLE
W HLE z narzedziami Opus 4.6 (53.1%) nieznacznie pokonuje Gemini (51.4%). To istotne — sugeruje, ze Claude lepiej laczy rozumowanie z faktycznym uzyciem narzedzi, co jest kluczowe w zastosowaniach agentowych wymagajacych precyzji.
Niezawodnosc w produkcji
Warto wspomnisc o danych z Replit: Claude 4 osiaga 0% error rate w ich srodowisku — dlatego GitHub Copilot Agent korzysta wlasnie z Claude. To nie jest benchmark, ale signal z produkcji na duzej skali, ktory mowi wiecej niz niejedna tabela wynikow.
Cena — gdzie Google zmienia zasady gry
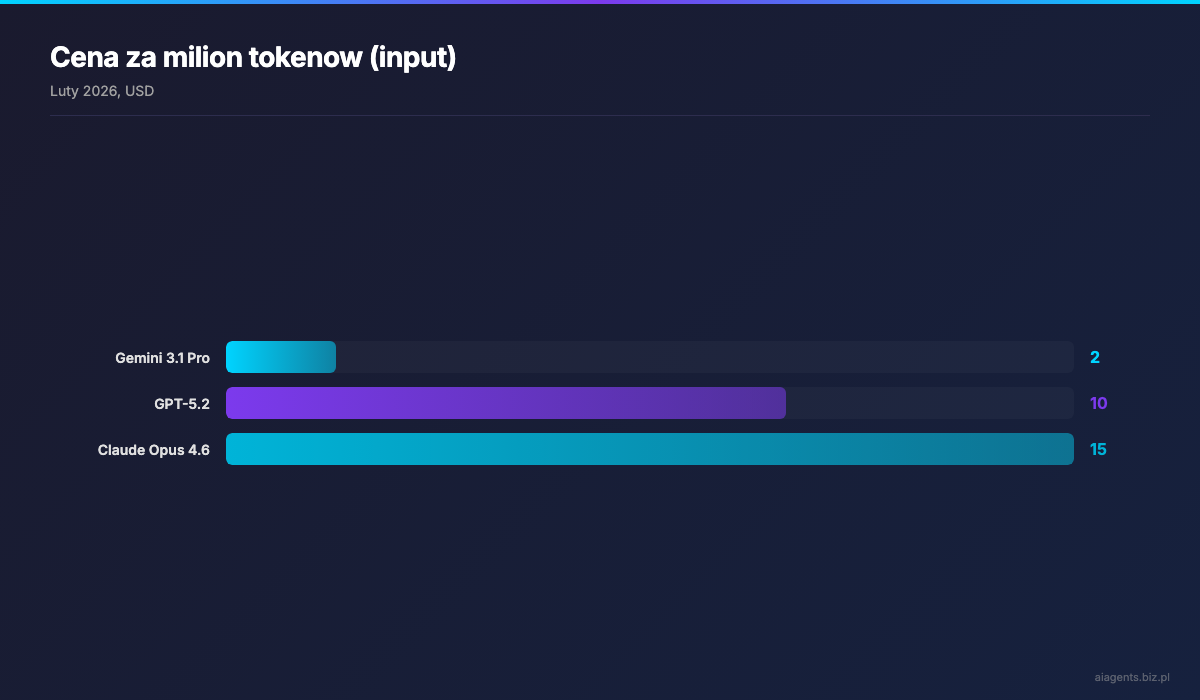
Zestawienie kosztow za milion tokenow:
Stosunek wydajnosc/cena
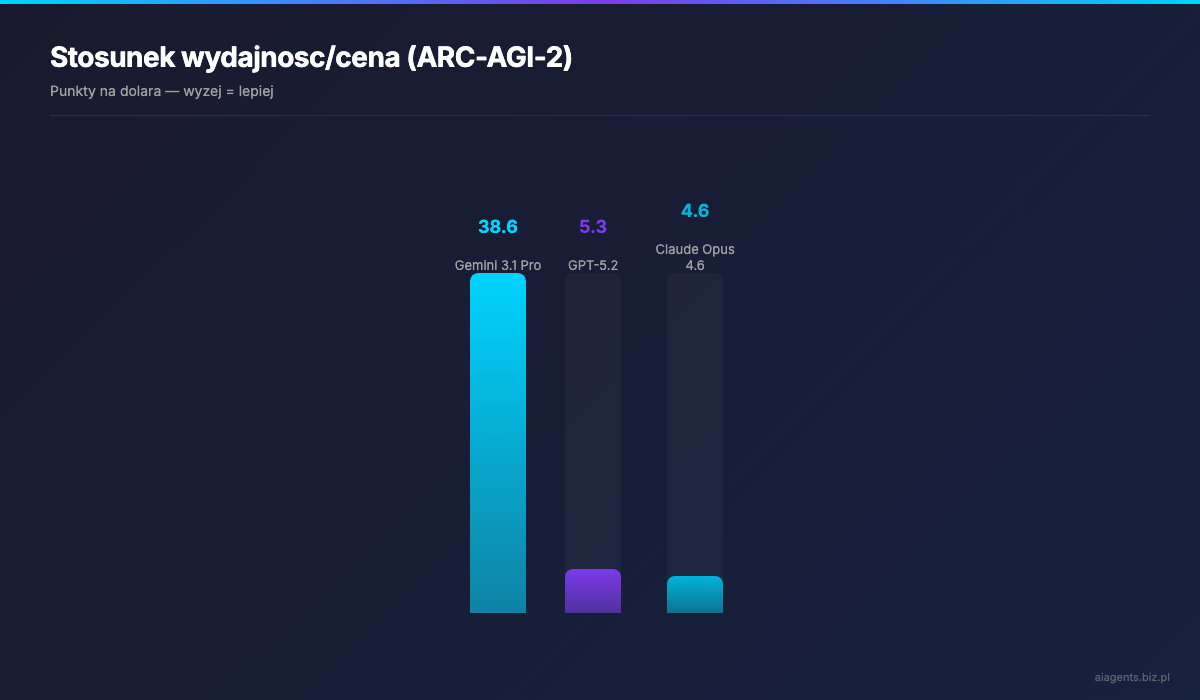
Jesli wezmiemy ARC-AGI-2 jako miare rozumowania i podzialimy wynik przez cene inputu:
- Gemini 3.1 Pro: 77.1% / $2 = 38.6 punktow na dolara
- Claude Opus 4.6: 68.8% / $15 = 4.6 punktow na dolara
- GPT-5.2: 52.9% / $10 = 5.3 punktow na dolara
Gemini oferuje ponad 8 razy lepszy stosunek wydajnosci do ceny niz Opus w zadaniach rozumowania. To argument, ktory jest trudny do zignorowania, szczegolnie dla startupow i mniejszych zespolow.
Ale jesli liczymy to samo dla GDPval-AA (jakosc komunikacji), obraz wyglada inaczej — tam Claude oferuje jakość, ktorej Gemini po prostu nie dorownuje, niezaleznie od ceny.
Co to oznacza dla developerow i firm
Dla startupow i mniejszych zespolow
Gemini 3.1 Pro to oczywisty wybor, jesli budzetowa efektywnosc jest priorytetem. Przy $2/$12 i milionowym kontekscie, mozna budowac aplikacje RAG, analize dokumentow czy chatboty, ktore przy Opus kosztowaloby wielokrotnie wiecej.
Dla zespolow inzynieryjnych
Obraz jest bardziej zlozony. Gemini prowadzi w SWE-Bench Verified (80.6%), ale GPT-5.3-Codex dominuje w Terminal-Bench (77.3%) i SWE-Bench Pro (56.8%). Claude utrzymuje 0% error rate w Replit. Wybor zalezy od konkretnego workflow — realne bugi (Gemini), zaawansowane problemy (GPT), niezawodnosc produkcyjna (Claude).
Dla zastosowań agentowych
Gemini z najlepszymi wynikami w APEX-Agents (33.5%), MCP Atlas (69.2%) i BrowseComp (85.9%) to mocny kandydat na "mozg" agenta AI. Ale HLE z narzedziami (Opus 53.1% vs Gemini 51.4%) sugeruje, ze w precyzyjnym tool use Claude moze byc bezpieczniejszy.
Strategia multi-model
Najbardziej pragmatyczne podejście w lutym 2026: uzywaj roznych modeli do roznych zadan. Gemini do rozumowania, analizy dlugich dokumentow i zadan agentowych. Claude do komunikacji z uzytkownikami i niezawodnego kodowania. GPT-5.3-Codex do zaawansowanych zadan terminalowych. Trzy thinking levels w Gemini ulatwiaja routing — low do prostych pytan, high do zlozonych problemow.
Podsumowanie
Google Gemini 3.1 Pro to najwazniejsza premiera AI w lutym 2026 — nie dlatego, ze jest najlepszy we wszystkim, ale dlatego, ze fundamentalnie zmienia rownanie cena-jakosc. Podwojenie wyniku ARC-AGI-2 wzgledem poprzednika (z 31.1% do 77.1%) przy cenie $2 na milion tokenow to wyrazny sygnal: era, w ktorej najlepsze rozumowanie kosztowalo $15+, dobiega konca.
Ale dane sa jednoznaczne takze w drugą stronę. Claude Opus 4.6 i Sonnet 4.6 zdecydowanie prowadza w preferencjach uzytkownikow (GDPval-AA). GPT-5.3-Codex dominuje w zaawansowanym kodowaniu. Claude ma 0% error rate w produkcji Replit.
Uczciwy werdykt: Gemini 3.1 Pro to najlepszy model rozumowania w swojej cenie i poważny pretendent do tytulu najlepszego modelu ogolnego. Ale "najlepszy" zalezy od tego, co mierzysz. Jesli mierzysz stosunek wydajnosci do ceny — Gemini wygrywa z ogromna przewaga. Jesli mierzysz jakosc komunikacji i niezawodnosc — Claude nadal prowadzi. Jesli potrzebujesz zaawansowanego kodowania — GPT-5.3-Codex nie ma sobie rownych w Terminal-Bench.
Wyscig modeli AI w 2026 roku nie ma jednego zwyciezcy. Ma trzech silnych graczy, z ktorych kazdy dominuje w innej dziedzinie. I to jest najlepsza wiadomosc dla calej branzy.
Powiązane artykuły
AI News22 lut 2026
Gemini 3.1 Pro — Google za $2 pokonuje modele za $75. Ale nie we wszystkim
Google Gemini 3.1 Pro podwoil wynik rozumowania i kosztuje 7.5x mniej niz Claude Opus 4.6. Pelne porownanie z liczbami i tabelami.
Czytaj dalejAI News22 lut 2026
Gemini 3.1 Pro — Google za $2 pokonuje modele za $75. Ale nie we wszystkim
Model za 2 dolary, ktory pokonuje flagowce kosztujace 7.5x wiecej. ARC-AGI-2: 77.1% vs 68.8% Claude. Ale GDPval-AA i Terminal-Bench mowia inna historie.
Czytaj dalejAI News22 lut 2026
Claude Opus 4.6: benchmarki, milion tokenow i agenci AI
Claude Opus 4.6 od Anthropic zmienia zasady gry: milion tokenow kontekstu, Agent Teams i najlepsze wyniki w benchmarkach agentowych. Sprawdz twarde dane.
Czytaj dalejAI News22 lut 2026
Nowości AI 2026 - nowe modele, agenty i rewolucja open-source
Nowości AI 2026 - nowe modele, agenty i rewolucja open-source W ciągu ostatnich trzech miesięcy branża AI wypuściła więcej przełomowych modeli niż przez cały 2024 rok. Rynek agentów AI przekroczył ...
Czytaj dalej